-- 发布时间:12/31/2008 8:17:00 PM
-- 关于blank node 的探讨
Blank Node
Pro (from the point of RDF ):
1.It's not necessary to assign an URI for those resources which don't have an obvious name. For example, there is an statement saying “Olympic takes place in Beijing. 2008”. it's impossible to describe this statement in a RDF triple. However, you can create a RDF graph as follows:
图1
here, a blank node is introduced without assigned any URI, because it's necessary.
2.It's neither necessary to assign an URI for those throw-away resources, which are locally used and later will be threw away.
Cons:
1.(from the point of Logics): what does a blank node mean?
For example: given a RDF triple
图2
Is it expressed either ∃like.Music or ∀like.Music, It's not clear from the point of Description Logic. That's why OWL language doesn't allow variables
2. (from the point of RDF): It can be referenced.
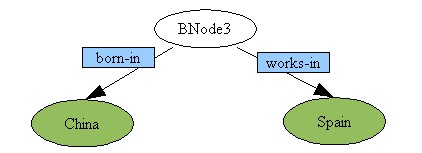
For example:given a RDF graph:
图3
Once this RDF graph is published into Web, nobody else can update more information about the Bnode3 but only the author him/herself. In another word, any access from outside of this graph is disallowed.
3.(from the point of RDF tools): Blank nodes are also meaningless for RDF tools,for instance Jena. That's because a new inside identifier is created each time when the graph is loaded into Jena, so that the identifier of a blank node is dynamicly changed and doesn't have any sense.
4.(from the point of SPARQL): The existence of bland nodes causes a problem when a query is written in SPARQL, since it's a illegal to let a blank node in the graph pattern. Especially, if there are several related SPARQL queries executed sequentially, as we have known that the identifiers of blank nodes are available, therefore, there is no meaning to put a blank node in a graph pattern. For another example, if you want to delete a triple involved with a blank node by Virtuoso. It's impossible to execute the commend like “Virtuoso.delete (?, age, 22)”. So blank nodes make modification of data difficult and even impossible.
5.(from the point of RDF Graph Merge): Since the identifier of a blank node is only visible inside the graph which include the bland node, the merge of two RDF graphs would be neither sound nor complete. Because on the one hand, if there are two triples from two graphs have the same subject, the same predicate, the same object by chance, where one of them is a bland node, it's not sure that there are the same, since different blank nodes can have same identifier created inside each graph. On the other hand, it's possible to be the same triple with different identifiers in two triples.
Above all, a blank node provides convenience for people who creates them, in the meanwhile, it causes many problem for other people who want to consume them.
[/QUOTE][/QUOTE] 此主题相关图片如下:
此主题相关图片如下: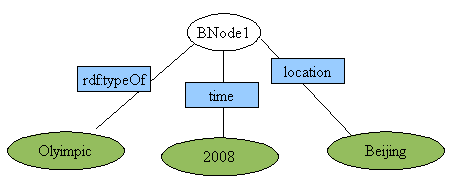
 此主题相关图片如下:
此主题相关图片如下: 此主题相关图片如下:
此主题相关图片如下: