-- 发布时间:3/11/2008 6:28:00 PM
-- [推荐] Windows Mobile上的XML相关类
本文主要介绍Windows Mobile上的XML相关类,并介绍如何利用它们高效地操作XML文件(流)。关于XML本身的语法和用法我就不在此赘述了,首先,我们来看一看 .NET Compact Framework 的System.XML这个命名空间下,为我们操作XML提供了哪些类型支持:
| XmlReader 抽象类,提供了快速,单向,只读的读取XML文件流操作 XmlWriter 抽象类,为生成一个XML文件流提供了接口 XmlTextReader 继承于XmlReader,用于格式良好的XML文本处理 XmlTextWriter XmlWriter的一个实现类 XmlNodeReader 公共类,用于处理内存中的XML DOM Tree XmlNodeWriter 公共类,用于在内存中产生XML DOM Tree XmlDocument 一个XML DOM Tree的模板类 |
先来看那个名字跟其他几个类不太一样的吧:XmlDocument.
XmlDocument 用于把XML文件加载到内存中间。调用Load()方法即可将XML文件作为一个数据树加载到内存。Load()方法提供了几个重载,你可以通过文件名,任意流,或从XmlReader继承的类以及System.IO.StreamReader和TextReader来Load。这里需要区别一下的是另一个方法LoadXml(),它是用来加载Xml字符串的,而不是文件!
下面的例子是从XmlTextReader去Load 一个XML文件:这里提到了XmlTextReader 这个类,可以说XmlTextReader 是XmlReader在细粒度控制方面的一个实现。XmlTextReader 包含了当前节点的位置信息。调用它的Read()方法,讲从文件中读取下一个节点的信息,读取顺序是“深度优先”的。通常,在读取数据之初,我们会调用MoveToContent() 去跳过一些非数据的元素段,直接到达根节点处,调用Skip()方法会跳过当前界点的所有分节点,这在检索节点的时候可能会用得到,可以跳过一些不必要的子节点而节约一点性能,但是对设备上小规模的XML文件,这个效果往往不是太明显。不过显然可以理解,这种不需要加载整个文件的单向的读写方式,要比使用XmlDocument对象要快得多。
XmlDocument xmldoc = new XmlDocument();
XmlTextReader xmlRdr = new XmlTextReader(@""Storage Card"books.xml");
xmlRdr.WhiteSpaceHandling = WhiteSpaceHandling.None;
xdoc.Load(xmlRdr);
说到性能,对于资源有限的设备来说,这显然是不可忽略的一点,在操作XML的时候,我们也应考虑到这一点,在使用XmlReader和XmlWriter的时候,可以使用XmlReaderSettings和XmlWriterSettings来调整性能,例如使用IgnoreWhiteSpace来忽略空白字符,或着使用IgnoreComments来忽略注释行等等,
另外需要注意的是,如果我们使用XmlReader来读取的时候要避免使用Schema,因为在单向读取的时候,Schema的校验会损失一部分性能,而用DataSet来读取的时候,尽量使文件包含Schema来确定表结构,这样读起来会比较快,不需要编译器来为Dataset创建架构。
从细粒度方面考虑,可以用MoveToAttribute()来设置XmlReader的访问点,访问各个属性。例如:
public void ShowAttributes(XmlReader reader)
{
if (reader.HasAttributes)
{
Console.WriteLine("Attributes of <" + reader.Name + ">");
for (int i = 0; i < reader.AttributeCount; i++)
{
reader.MoveToAttribute(i);
Console.WriteLine(reader.Name+"::"+reader.Value);
}
reader.MoveToElement(); //属性访问完毕后让reader返回到元素节点上来
}
}
XmlNodeReader 和XmlNodeWriter 对XmlNode提供了快速非缓存的访问方式,可以直接从Xml的Stream获取信息。好,再来看一个例子:
 此主题相关图片如下:
此主题相关图片如下: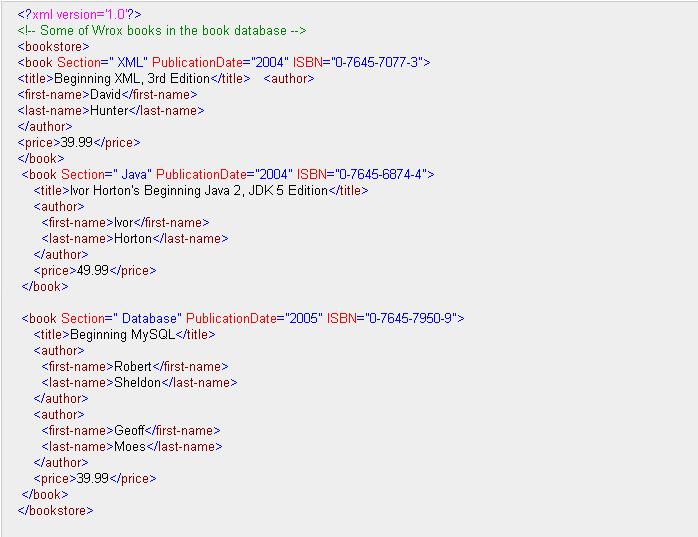
1) 使用 XmlTextReader
这个XML文件包含了几本书(book)的相关信息,书有分元素title,author,prize和属性Section,PublicationDate,ISBN。我现在想做的事情就是把这个XML文件的内容按照我预定的格式打印出来,并存放到一个output.txt文本文件里面:
首先,我们定义两个用于读写的reader和writer,在处理函数里面,首先我们做一个初始化:当reader在读的时候以下是FormatOutput函数:
程序界面;
XmlTextReader reader = null;
StreamWriter writer = null;
writer = newStreamWriter(@""Storage Card"output.txt",false);
reader = newXmlTextReader(@""Storage Card"books.xml");
while (reader.Read())
{
//XmlNodeType这个枚举让我们方便的对不同类型的节点进行相应的操作
switch (reader.NodeType)
{
caseXmlNodeType.XmlDeclaration:
FormatOutput(writer, reader, "XmlDeclaration");
break;
caseXmlNodeType.ProcessingInstruction:
FormatOutput(writer, reader, "ProcessingInstruction");
break;
caseXmlNodeType.DocumentType:
FormatOutput(writer, reader, "DocumentType");
break;
caseXmlNodeType.Comment:
FormatOutput(writer, reader, "Comment");
break;
caseXmlNodeType.Element:
FormatOutput(writer, reader, "Element");
break;
caseXmlNodeType.Text:
FormatOutput(writer, reader, "Text");
break;
caseXmlNodeType.Whitespace:
break;
}
private static void FormatOutput(StreamWriter writer, XmlReader reader, String nodeType)
{
//用tab使输出的层次分明一点
for (int i = 0; i < reader.Depth; i++)
{
writer.Write('"t');
}
//这里并没有做过多的判断,但是作为Element的节点并没有Value
if (reader.Name != String.Empty)
writer.WriteLine(reader.Prefix + nodeType + "<" + reader.Name + ">:" + reader.Value);
else
writer.WriteLine(reader.Prefix + nodeType + ": " + reader.Value);
// 显示当前节点的属性名和值,同样用tab做了格式控制
while (reader.MoveToNextAttribute())
{
for (int i = 0; i < reader.Depth; i++)
writer.Write('"t');
writer.WriteLine("Attribute: " + reader.Name + "= " + reader.Value);
}
}
此主题相关图片如下:
输出效果:
XmlDeclaration<xml>:version='1.0'
Attribute: version= 1.
Comment: Some of Wrox books in the book database
Element<bookstore>:
Element<book>:
Attribute: Section= XML
Attribute: PublicationDate= 2004
Attribute: ISBN= 0-7645-7077-3
Element<title>:
Text: Beginning XML, 3rd Edition
Element<author>:
Element<first-name>:
Text: David
Element<last-name>:
Text: Hunter
Element<price>:
Text: 39.99
Element<book>:
Attribute: Section= Java
Attribute: PublicationDate= 2004
Attribute: ISBN= 0-7645-6874-4
Element<title>:
Text: Ivor Horton's Beginning Java 2, JDK 5 Edition
Element<author>:
Element<first-name>:
Text: Ivor
Element<last-name>:
Text: Horton
Element<price>:
Text: 49.99
Element<book>:
Attribute: Section= Database
Attribute: PublicationDate= 2005
Attribute: ISBN= 0-7645-7950-9
Element<title>:
Text: Beginning MySQL
Element<author>:
Element<first-name>:
Text: Robert
Element<last-name>:
Text: Sheldon
Element<author>:
Element<first-name>:
Text: Geoff
Element<last-name>:
Text: Moes
Element<price>:
Text: 39.99
2) 使用 DataSet
跟在PC机上一样,在面临复杂数据交互,需要充分利用数据间的相互关系的时候,单向运行的XmlReader就有些不够用了,因为它不保存“流过去”的信息,做过ADO.NET的人对DataSet应该不会陌生,跟XmlReader不同,DataSet就是一个常驻内存的关系型数据库。DataSet里面的数据即可以来自关系型数据库又可以来自XML文件(流)。下面的意思演示了如何从DataSet加载XML并在DataGrid上面显示出来:
1 DataTable dt1 = null;
2 DataTable dt2 = null;
3 DataSet ds = null;
4 int CurrentTable ;
5 public Form2()
6 {
7 InitializeComponent();
8 }
9
10 private void LoadData()
11 {
12 int loadTimeSpan;
13
14 XmlDocument doc = new XmlDocument();
15 try
16 {
17 int t1= System.Environment.TickCount;
18 //将XML文件读入内存
19 doc.Load(@"\Storage Card\books.xml");
20 int t2 = System.Environment.TickCount;
21 loadTimeSpan = t2 - t1;
22 MessageBox.Show("LoadDocTimeSpan:"+loadTimeSpan);
23 }
24 catch (XmlException ex)
25 {
26 MessageBox.Show(ex.Message);
27 return;
28 }
29 Cursor.Current = Cursors.WaitCursor;
30 //通过XmlNodeReader把XmlDocument中的数据填充到dataSet中去
31 XmlNodeReader reader = new XmlNodeReader(doc);
32 int DataSetFillSpan;
33 ds = new DataSet();
34 int t3 = System.Environment.TickCount;
35 ds.ReadXml(reader);
36 int t4 = System.Environment.TickCount;
37 DataSetFillSpan = t4 - t3;
38 reader.Close();
39
40 //因为XML文件里面存在Book和Author的一对多的主从表
41 dt1 = ds.Tables[0];
42 dt2 = ds.Tables[1];
43 //设置默认显示的表
44 DG_Book.DataSource = ds.Tables[0].DefaultView;
45 CurrentTable = 0;
46 Cursor.Current = Cursors.Default;
47 MessageBox.Show("Fill dataset timeSpan:"+DataSetFillSpan);
48 }
49
50 private void Form2_Load(object sender, EventArgs e)
51 {
52 LoadData();
53 }
54
55 /**//// <summary>
56 /// 显示特定行的信息
57 /// </summary>
58 /// <param name="bookIndex">行号</param>
59 private void DisplayDataRow(int bookIndex)
60 {
61 String line = String.Empty;
62 DataTable dt = CurrentTable == 0 ? dt1 : dt2;
63
64 DataRow dr = dt.Rows[bookIndex];
65
66 int col = 0;
67 foreach (object value in dr.ItemArray)
68 {
69 line += (dt.Columns[col].ColumnName + ": " +
70 value.ToString() + "\r\n");
71 col++;
72 }
73 MessageBox.Show(line);
74 }
75
76 private void menuItem3_Click(object sender, EventArgs e)
77 {
78 int bookIndex = DG_Book.CurrentRowIndex;
79 DisplayDataRow(bookIndex);
80 }
81
82 private void menuItem4_Click(object sender, EventArgs e)
83 {
84 SwitchTable();
85 }
86
87 private void menuItem5_Click(object sender, EventArgs e)
88 {
89 SwitchTable();
90 }
91
92 /**//// <summary>
93 /// 在两个表之间切换显示
94 /// </summary>
95 private void SwitchTable()
96 {
97 if (CurrentTable == 0)
98 {
99 DG_Book.DataSource = dt2.DefaultView;
100 CurrentTable = 1;
101 this.Text = "Author Table:";
102 }
103 else
104 {
105 DG_Book.DataSource = dt1.DefaultView;
106 CurrentTable = 0;
107 this.Text = "Book Table:";
108 }
109 }
110
111 private void menuItem1_Click(object sender, EventArgs e)
112 {
113 //关闭的时候输出带Schema的XML文件
114 if (ds != null)
115 {
116 ds.WriteXml(@"\Storage Card\bookstore.xml", XmlWriteMode.WriteSchema);
117 //ds.WriteXmlSchema(@"\Storage Card\bookstore.xsd");
118 }
119 Application.Exit();
120 }
此主题相关图片如下: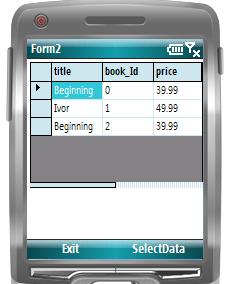
最后有一点是要强调的是,在使用DataSet的时候,一定要考虑的数据量的大小,可能超过2K以上的数据加载的时候速度就有点不能忍受了。我在模拟器上测试用的不到1k的数据生成XmlDocument用了1.5秒,填充DataSet用了8秒多,当然在设备上还是要比这快一些。